Why is my EFS slow?

If you have started using EFS as the main root storage for your application such as your WordPress website, or a common storage layer for your containerized applications, you may notice that the performance obtained when using the EFS appears to be slower than using regular disks. This slowness is not caused deliberately, rather it is due to the nature of EFS.
Using EFS without being aware of it's architecture and limitations can catch you unawares, however, by understanding how EFS works and the nature of your application, it is possible to boost the performance of your application using EFS (notice I said application performance and not EFS performance.)
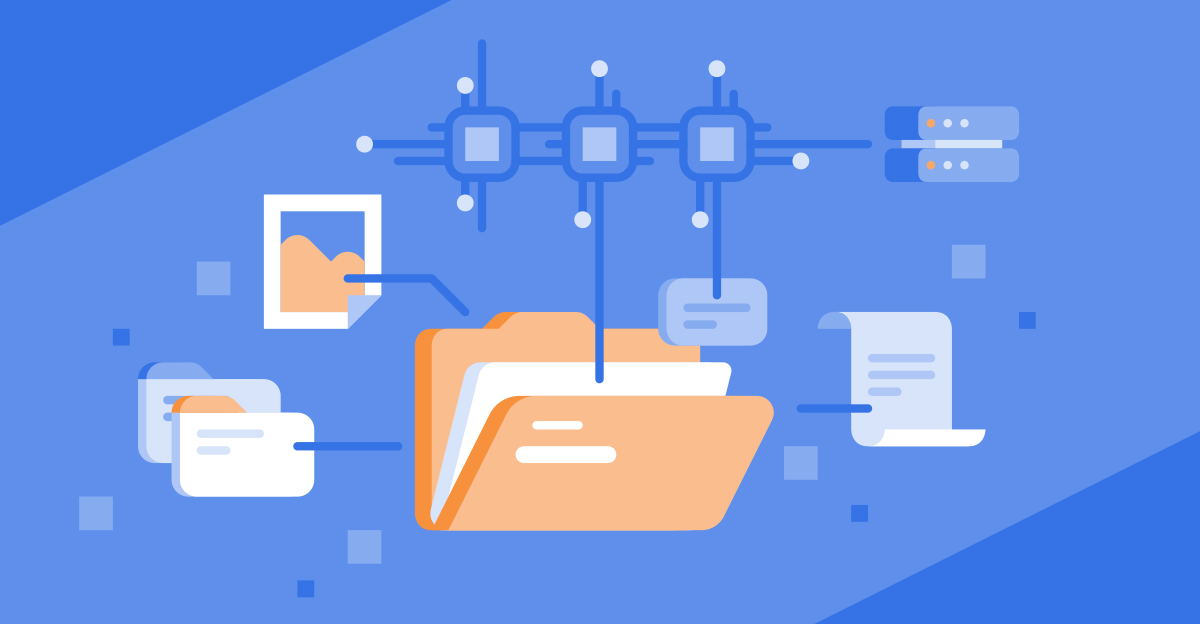
EFS Architecture
Straight from AWS' documentation, EFS is a distributed file system which is designed to be accessed by thousands of clients simultaneously, provide redundant and highly available storage across multiple availability zones, and provide low latency per-file operation. The latter of these claims otherwise towards the slowness experienced, however the key-words to remember is "per-file operation". It is an NFS file system, and is designed to be accessed via the NFS protocol. Supported versions of the protocol are NFS version 4, and NFS version 4.1 (preferred).
EFS manages all file storage infrastructure for you, and you only pay for the storage that you use. You do not have to provision any servers or instances, nor do you have to manage any storage or disks. It also guarantees "close-to-open" data consistency and supports POSIX permissions.
Understanding "per-file operation" latency
To understand why per-file operation latency can induce slowness, we first need to understand how the operating system works with files in general. EFS, at present, can only be accessed by Linux-based clients, and every single component of Linux, be it an application or configuration, consists of files. In short, every action on your Linux operating system requires accessing a file.
Unpacking that analogy, there are only two options which are applicable to the use of files; reading, and writing to a file. From the operating system's point of view, either of these actions is interpreted as an "operation", and there are appropriate read and write operations available as the operating system would need to perform different actions for these operations. This is unpacked further here (coming soon).
When reading or writing to a file, the operating system needs to first obtain the metadata for the file, which contains various information about the file including the inode of the file, the permissions to determine if the file is accessible by the user or application performing the operation, as well as the block size and IO block (location on the disk) for the actual data on the file. If the user or application has sufficient permissions to access the file, the operating system would then access the contents of the file from the disk.
Coming back to EFS, we know that EFS uses the NFS protocol to run file operations. What you may not know, is that NFS is not too efficient with handling metadata, which is necessary for all file operations. To briefly explain, your file would be located within a directory, such as the root EFS directory or several directories within the EFS. When trying to access a file, the NFS protocol will recursively check each directory to determine if the user has sufficient permissions to access each directory, before finally arriving at the specified file. As you are connecting to the EFS over a network, each of these checks is a Remote Procedure Call (RPC). As these checks occur over a network, while these checks occur very fast, they are much slower when compared to directly attached storage options. A deeper overview of the NFS protocol sequence is explained here.
What's next?
Now that we understand what causes latency with the EFS, we can go ahead and start looking methods for improving the performance of the applications which use the EFS. This is discussed in the second part of this blog post.

Comments